

计算机学会通讯编者按:自2016年以来,周伯文教授及其团队持续深入研究agi的实现路径;当前,面对大语言模型在scaling law与架构等方面的技术瓶颈,周教授及其团队不仅提出了完整的agi实现路径,更创新性地从应用价值出发,探索更高效发挥agi潜力的场景与方法。
本文详细介绍了这一原创性路径及其技术研究,为agi的未来发展提供新的纵深视角与实践参考。
人工智能突破从哪里来,
未来向何处发展?
前沿学者们对大语言模型的能力边界进行了持续讨论。例如,图灵奖得主yann lecun常提及,机器学习目前存在诸多短板,他的研究偏重泛化性,关注如何尽量达到人类的智能。而deepmind强化学习团队负责人david silver提到,要做到superhuman intelligence(超人类人工智能)以及发现更多新知,大语言模型尚且存在局限,仍有许多工作有待完成。在这里,他强调的是如何在一些专业领域实现superhuman intelligence,并不是具备更强的通用能力。

因此,在当下这一时间节点,探讨agi的实现方向及其关键问题,具有重要的意义。我最早对agi发展路径的思考作公开分享是在2016年,当时我正担任ibm总部的人工智能基础研究院负责人。在那一年的town hall meeting上,我提出人工智能的发展会经历三个阶段,分别为狭义人工智能(ani)、广义人工智能(abi),以及通用人工智能(agi)。

周伯文教授在2016年提出,人工智能的发展会经过ani、abi、agi三个阶段
当时我的判断是,基于深度学习的监督算法仅能实现狭义人工智能,因其在任务间的迁移和泛化能力极为有限,并且需要大量标注数据。另一方面,2016年,agi还是非常模糊的愿景,全世界只有极少数研究者谈论,我个人当时给出agi的定义是比人类更聪明,会独立自主学习,并且一定需要更好地治理和监管——这点非常明确。但怎样从狭义人工智能走向agi,我判断中间有一个必经阶段,并将其称之为abi,即广义人工智能。这应该是abi概念被首次提出,因此我也给出了三个必备要素的定义:即自监督学习能力、端到端能力,以及从判别式走向生成式。尽管2016年时狭义人工智能进展明显,但因为判断其能力存在上限,我当时呼吁ai研究者尽快从狭义人工智能,转向探索广义人工智能。回过头看2022年底出现的chatgpt,以上三个要素基本都已具备,所以可以认为基于scaling law的大模型较好地实现了广义人工智能。但当时我本人未曾预料其具备如此强大的涌现与零样本学习能力,尽管我曾提到abi应该具备优秀的小样本学习能力。认知决定行动,行动取得结果,有了上述判断,我的团队在2016年转向广义人工智能研究,开始思考如何让模型更好地泛化,随后在2016年底提出了多头自注意力机制的原型(a structured self-attentive sentence embedding, https://arxiv.org/abs/1703.03130),并首先应用在与下游任务无关的自然语言表征预训练中。
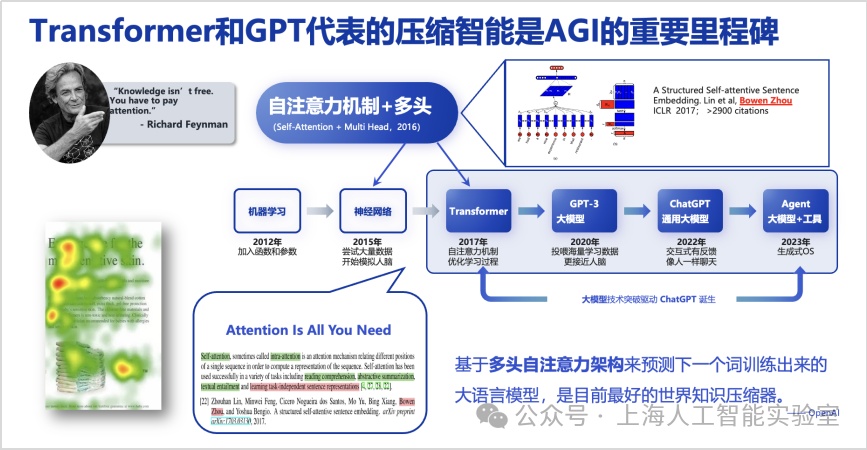
研究团队认为,模型在思考过程中能更灵活、多样、有效地使用元动作,是模型在推理阶段能够利用更多思考时间解决更复杂任务的重要原因。transformer完善了多头自注意力架构,但其价值的放大,来自于openai的研判。openai发现并认为,基于多头自注意力架构用于预测下一个词,由此训练出来的大语言模型是目前最好的世界知识压缩器。站在2019-2022年的视角,这个认知非常前沿,是实现压缩智能的基础。我们可以认为transformer和gpt代表的压缩智能是agi的重要里程碑。但毫无疑问,仅靠压缩智能远远不能实现agi。google deepmind发表于2023年的论文(levels of agi: operationalizing progress on the path to agi. 2023),将agi进行了分级。一方面借用了我们提出的从狭义人工智能到通用人工智能对比的概念,另外一方面在专业性上将人工智能分成了6个级别,从不具备ai能力即纯粹编程,到superhuman level(“超人类”水平)。
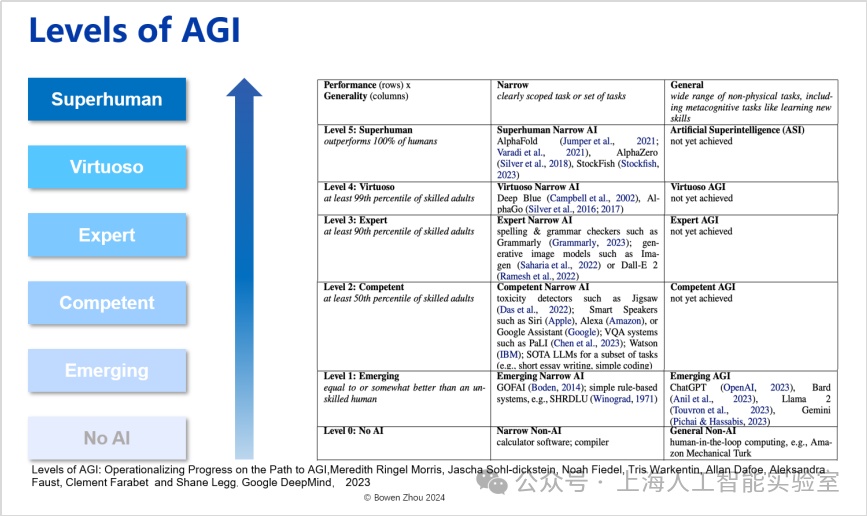
google deepmind把agi分为6个等级
可以看出,chatgpt虽然有很好的泛化性,但在智力水平只属于第一级emerging level(“初现”),还达不到第二级competent level(“和人类相当”)——后者的定义是超过50%的人类。再往上为expert(专家级),是指超过90%人类的水平;virtuoso(魔术师级)是指超过99%人类;而所谓superhuman(超人类)是指在该领域可以超越所有人类——如同最新版的alphafold一样,人类无法在蛋白质折叠这个领域再击败ai了。
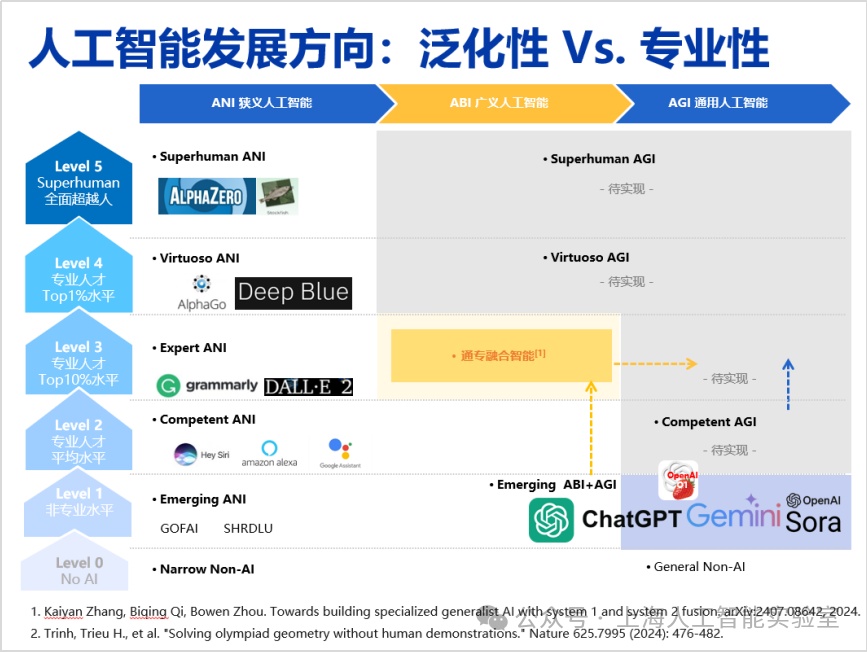
但类似alphafold这种专业性极强的ai,其泛化性往往较为有限。若将泛化性与专业性结合考虑,可以形成一个二维概念框架。我们注意到,chatgpt和sora在泛化性方面取得了显著进展,但在专业性方面仅达到人类15%-20%的水平。即便运用scaling law(规模律)进一步增加模型参数,其专业性的提升效果并不显著,而成本却显著增加。专业性不足不仅限制了创新,还会导致大量事实错误的出现。回顾人工智能七十余年的发展历程,我认为实现通用人工智能的路径可被视为一张二维路线图:横轴代表专业性,从ibm的深蓝到deepmind的alphago,在横轴方向(专业性)上取得了显著进展;但这些工作的泛化性一直较为薄弱,限制了ai技术的进一步普及。
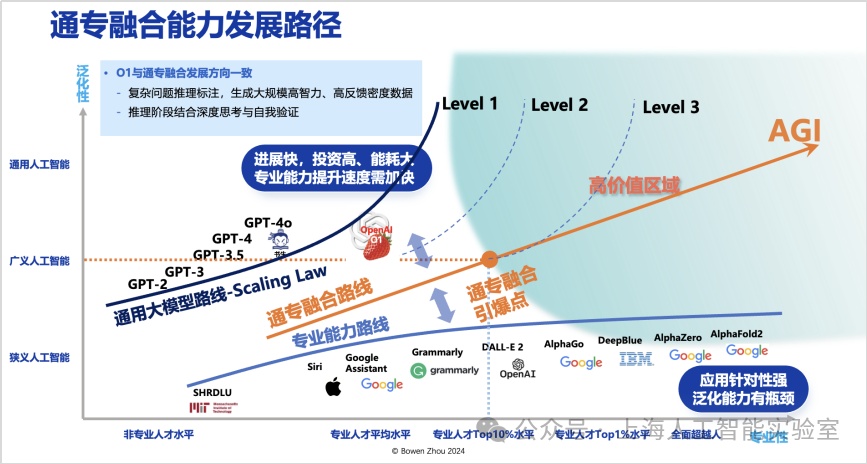
而从2016年多头自注意力,到transformer、chatgpt出现,压缩智能代表的是泛化性狂飙。但可以看出,它在专业性上的水平进展极其缓慢,scaling law很明显不足以延伸它的专业性,能力长期停留在level 1的左侧。
未来人工智能应当如何发展,并推动更大的价值创造?从2022年底,我在多个场合讲过,存在一个高价值区域,这个区域在横轴应达到或超过90%以上专业人士的水平。同时又具备能达到广义人工智能级以上的泛化能力,以极低成本在不同任务之间进行迁移。这个区域,即是agi路线图中的“高价值区域”。
这个区域离这张路线图出发最近的点,我称之为通专融合引爆点。是否存在一种路线,从当前技术出发,能更快地接近通专融合引爆点?我认为存在这样的路线,并将其称为通专融合技术路线。
虽然我们看到此前openai一直都是在scaling law的泛化性上持续推动,但今年也开始朝专业性方向迭代。从gpt-4o之后,将很多精力投入“草莓”系统的研究,开始沿着与通专融合相似的方向发展。
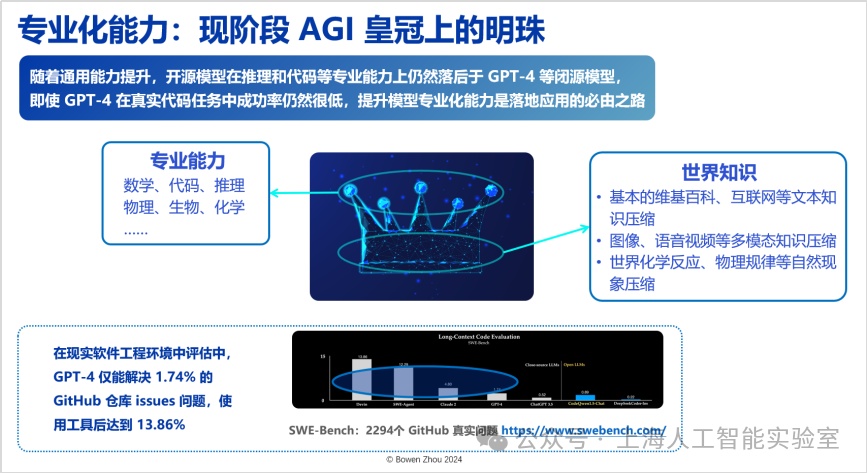
关于通专融合的目标,一方面,随着合成数据飞轮效应的加速,过去一年基础模型获取通用能力的难度显著降低;另一方面,在世界知识的压缩能力上,开源模型的性能已无限逼近闭源模型。然而,不管是开源还是闭源模型,在专业化能力方面仍存在显著瓶颈。例如,在实际的软件工程环境中,gpt-4仅能解决github中1.74%的人类提出的问题。即便通过引入大量工具、结合基础模型与工具型agent的方式,这一比例也仅提升至13.85%。
可以看到,目前对于世界知识进行压缩的智能发展路径正在自然演进,但我们认为在这之上的专业能力,才是现阶段agi皇冠上的明珠。
通专融合agi实现路径
我们提出的通专融合,不仅需要同时具备专业性和通用泛化性,还必须解决任务可持续性的问题,来让人工智能能高效地可持续发展,它们形成了通专融合技术挑战的三个顶点。

“通专融合”必须实现“通用泛化性”“高度专业性”“任务可持续性”三者兼得
自2023年初以来,我们提出了具体的通专融合实现路径(towards building specialized generalist ai with system 1 and system 2 fusion,https://arxiv.org/abs/2407.08642),该路径需要三个层次相互依赖,而非仅依靠单一模型或算法。对每一层我们都有整体规划与具体技术进展,不过由于时间关系不能一一展开,下面简要描述每一层的核心思想,以此完成对通专融合技术体系的拆解。
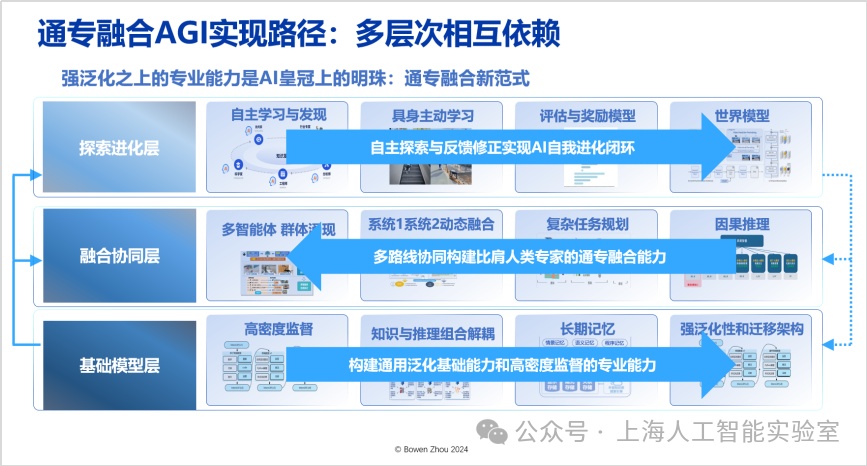
路径的第一层是“基础模型层”,这一层需要大量工作来改变现有架构。其中,最重要的是如何实现知识与推理的有效解耦与组合,同时实现高智力密度的监督信号,并在架构方面实现长期记忆——目前transformer难以实现长期记忆,通过改变现有架构,ai能够获得强大的泛化性和迁移能力。在基础模型的能力之上,具备通用的架构和学习能力,还需要高效的学习方法,才能更好地实现通专融合,这便进入了第二层“融合协同层”。自2017年以来,我们提出“系统1”和“系统2”(即“快思考”和“慢思考”)的动态融合,以解决更多问题。两种思考方式的动态融合最接近人类大脑的思考方式,也是从能耗和泛化角度而言最佳的方法。这里可以进一步延伸至多智能体协同,它不仅仅是单个系统1或系统2,多个智能体的协同在群体层面产生智能涌现,必须具备复杂任务的规划能力。
在融合协同层,需要脱离目前基于统计相关性的推断,转向因果推断,这是避免大模型能力瓶颈的有效方法。我们已经认识到,“压缩智能”并不代表所有智能。正如人类看再多的书和视频也无法学会游泳一样,要获得关于游泳的智能,就必须与物理世界互动,让物理世界的反馈影响肌肉记忆,直至大脑皮层。这种反馈自主学习与发现,就是我们所说的第三层“探索进化层”,这层的关键在于高效地获取反馈和奖励,即从真实环境中获得可持续、高置信的反馈信号。同时,我们还需要跨媒介可交互的世界模型来对物理环境进行建模。
通专融合关键技术
1、基础模型层的进化方向
高密度监督信号是专业化知识注入的关键。在基础模型层,必须高效引入高智力密度监督信号。在压缩智能学习方式下,容易让人误以为只需给出下一个词作为监督,模型就能高效学习。然而,这种学习方式在很多情况下只能让模型学会一种“快捷方式”(shortcut),它知道如何找到最佳答案,但对于“为什么这是最佳答案”,则缺乏系统化的思考。
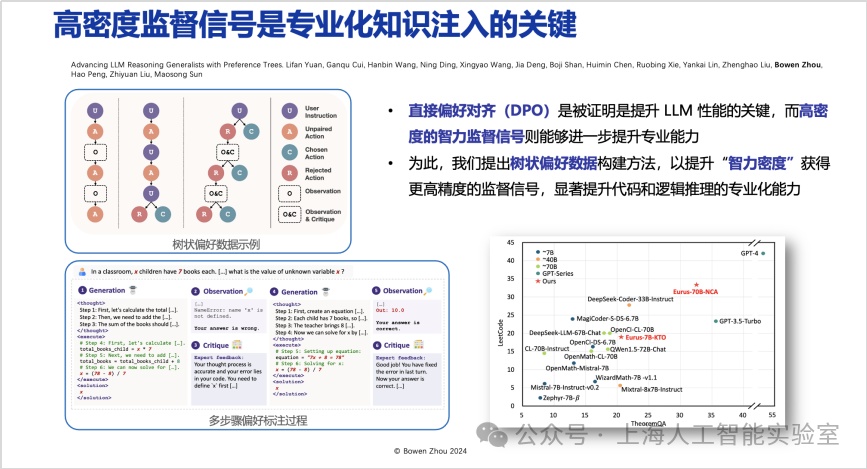
基于这一原因,在直接偏好优化阶段,我们提出了带有观测、批评、修改循环流程的树状偏好数据构建方法。在每个推理阶段,给模型提供多个选择并给出优先级,通过更高密度的监督,使模型在推理过程中学会更多可替代性的比较(advancing llm reasoning generalists with preference trees,https://arxiv.org/abs/2404.02078)。该方法在openai o1亮相前已公布,仔细研究会发现它采用了类似的高智力密度监督推理过程。这是为模型注入专业化知识的关键。
何为“专业”与“不专业”?前者意味着始终能在多个选择中找出最佳答案;而后者则仅能做出“最佳猜测”,常被其他待选项所混淆。(11月25日,上海ai实验室推出了能够自主生成高智力密度数据、具备元动作思考能力的强推理模型书生internthinker。该模型能在推理过程中进行自我反思和纠正,从而在数学、代码、推理谜题等多种复杂推理任务上取得更优结果。)
除了当前的主流结构外,高效的知识推理可组合可分离的架构更有利于构建可信赖、泛化、扩展的大模型。布罗德曼分区(brodmann area)是神经科学里面公认对大脑不同区域承担不同专业功能的分区架构。我们寻找的架构,应具备知识应用可信赖、推理过程可泛化、知识内容可拓展三种性质,同时能够有效地进行组合。transformer的一个优点在于,可实现推理与知识的高度融合,拥有很大的提升空间。但缺点也在于当知识和推理高度融合之后,一旦模型产生幻觉,将很难溯源。所以寻找一种新的架构极其重要。
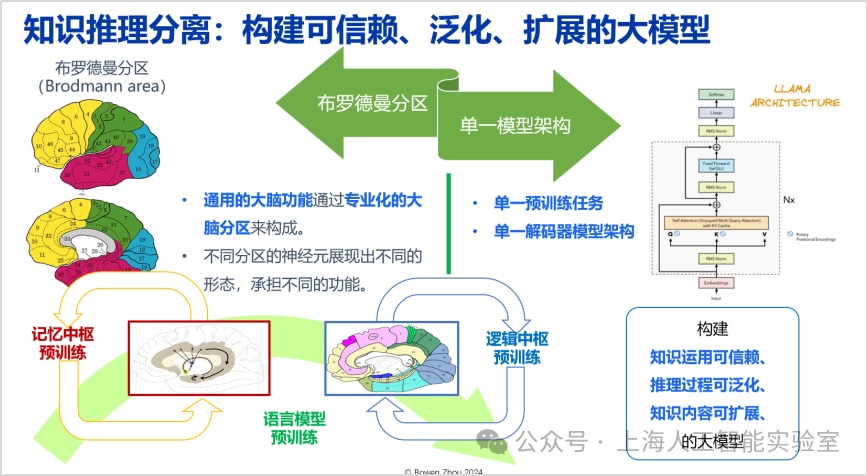
长期记忆机制是通专融合的中间桥梁,需要这样的机制在通用与专业能力之间架起一座兼容桥梁。目前,这种长期记忆机制在transformer架构中的表现并不充分,这方面我们有一系列工作(如我2015年的研究https://arxiv.org/abs/1510.03931,以及近期的工作https://arxiv.org/html/2408.01970)。
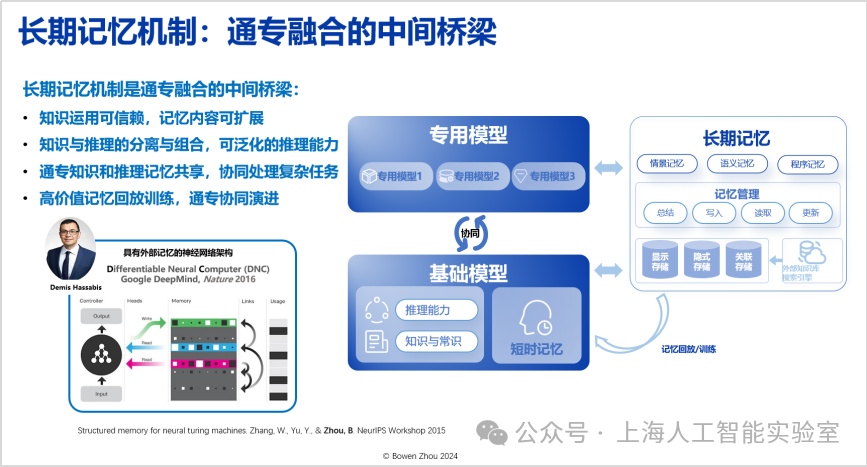
2、融合协同层
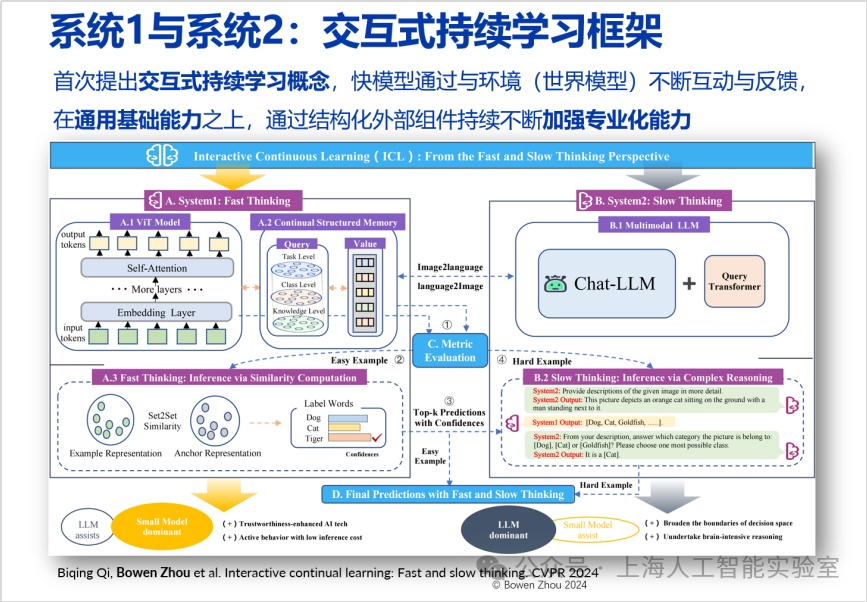
通专融合路径的第二层是融合协同层,特别强调快速处理和深度推理结合。在cvpr 2024收录的论文中,我们探索了这一领域(interactive continual learning: fast and slow thinking)。我们构建了一个高效识别图像的快系统(专用系统),当其遇到不确定的情况时,会将信息传递给一个更强大的慢系统(通用推理系统)。慢系统基于输入信息进行深度分析,并将结果反馈给快系统并在快系统中完成了一个结构化长期存储的更新。这种结合不仅降低了能耗,还提升了处理速度和准确率。
这种结合在处理速度和能耗上优于单独使用慢系统。许多问题快系统可自行回答,无需调用慢系统。此外,我们发现这种结合的准确度高于单独使用快系统或慢系统,这一发现颇具启发性。其潜力在于,快系统缺乏深度思考,易犯错;而慢系统对具体情况的判断不如快系统,许多细节不了解。通过快系统的输入,慢系统可排除不可能情况,做出更好判断。
快系统好比前线侦察员,提供具体输入信息;慢系统则相当于后方指挥官,具有更好的思考深度和判断能力。两者结合,可做出更准确高效的决策。这种结合不仅是简单叠加,而是深刻互动和理解。快系统从慢系统的输出中学习,并形成长期记忆;慢系统从快系统的输入中获得专业判断和背景。
上述系统不仅适用于图像识别,我们还尝试把将其应用于自然语言生成,让这样一个通专融合架构生成非常专业化的描述文字,例如某种疾病治疗方法、具体商品的营销策略等。
我们发现,专业模型承担了大部分任务。如下图所示,蓝色部分是专业模型生成的,红色部分则是专业模型“求助”通用模型进行泛化推理之后产生的。80%的内容由专业模型独立完成,而20%的慢推理对提升专业模型的泛化性有非常大的帮助(cogenesis: a framework collaborating large and small language models for secure context-aware instruction following. 2024)。
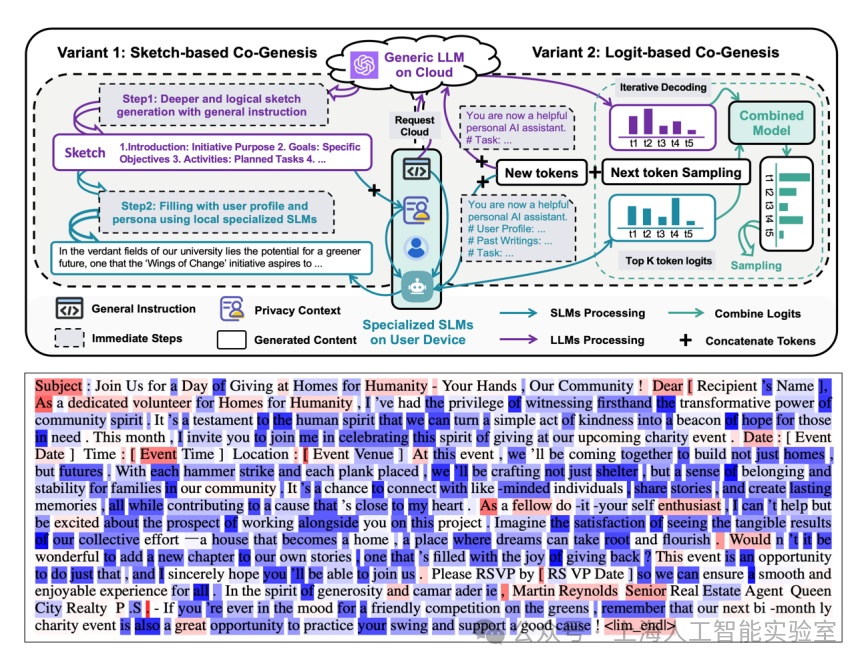
针对专业化个性内容生成任务,通用大模型仅对其中约20%的内容有贡献(纲要内容/推理能力,红色token),剩下80%内容则主要依赖专业化小模型生成(蓝色token)
3、探索进化层
正如前面提到,人类学会游泳必须与真实物理世界互动,ai也是如此。在这一层,我们尝试进行模型与环境长期实时交互,并进行具身自主探索与世界模型构建。比如上海人工智能实验室提出了开源且通用的自动驾驶视频预测模型genad,类似于自动驾驶领域的“sora”,能够根据一张照片的输入,生成后续高质量、连续、多样化、符合物理世界规律的未来世界预测,并可泛化到任意驾驶场景,被多种驾驶行为操控。在与物理世界的互动探索中,一方面我们深入物理世界,另一方面则在虚拟世界中通过模拟进一步提升效率。如具身智能训练,我们实现了在单卡上模拟训练一小时,相当于在真实物理世界训练380天的效率。这些成果通过首个城市级具身智能仿真训练场浦源·桃源进行了开放,欢迎大家在这个平台上训练专属的具身智能。

通专融合实践:科学发现
2023年1月5日《nature》发表的封面文章《papers and patents are becoming less disruptive over time》,文章提到,过去70年来论文数越来越多,专利数越来越多,但单篇论文的影响力却逐年下降,这不仅仅出现在计算机领域,也适用于生物、物理、化学等领域。
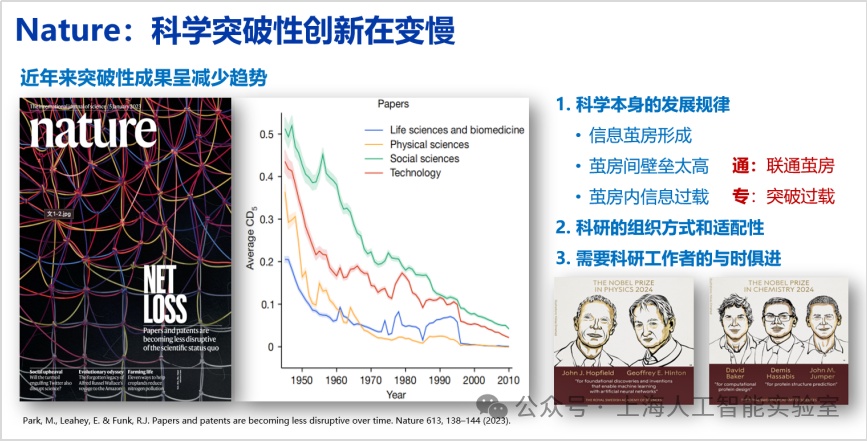
这篇论文只做了数据分析,没有追溯原因。对此我的个人思考是,该现象与科学发展规律密切相关。科学经过100余年的建设,已建成趋于完美的大厦,在大厦内部,每门子学科形成了非常强大的信息茧房,茧房间壁垒高,茧房内信息过载,所以导致论文与以前相比很难产生更广泛的影响力。解决这一问题,还需要对科研的组织方式和适配性进行适当调整。与此同时,也需要科研工作者与时俱进,用好ai新工具。我们有没有可能通过人工智能在技术层面帮助科学家获得更多突破?例如,人工智能的通用能力可以帮助人类解决信息壁垒太高的问题——因为人类的信息容量是有天花板的。茧房的信息过载的问题,则可以通过人工智能系统深度思考突破。
所以,通专融合是解决科学创新,开创下一代科学创新范式必须具备的能力。关于使用大模型开展科学创新,目前存在诸多问题,例如不确定性和幻觉。不过原openai联合创始人andrej karpathy认为,这种不确定和幻觉一方面可以被认为是大模型目前的不足,但另一方面则更像一个特性而非缺陷,这种幻觉与创造性相关,模型的幻觉可以与人类做梦类比。在科学历史上,德国有机化学家august kekul梦见衔尾蛇,进而发现苯环结构。这种发现的过程,从某种意义上讲,与大模型的幻觉具有很强的相似性,关键在于如何把幻觉的创造性用好,利用大模型的这种特点发挥价值。基于这些思路,我们过去几年来开展了一系列的工作,比如我们认为大语言模型是非常有效的零样本(zero-shot)科学假设的提出者。所谓零样本就是大模型可以提出全新、原创的科学假设。不一定像牛顿三大运动定律那样具有划时代意义,但模型确实能提出一些科学家没有发现和观察到的现象(如我们2023年的工作large language models are zero shot hypothesis proposers以及近期工作ultramedical: building specialized generalists in biomedicine)。例如,我们构建的全自动蛋白质组学知识发现系统proteus能结合真实的蛋白质组学数据,独立发现了191条经过专家评估的、具有自洽性、逻辑性和创新性的科学假设(https://arxiv.org/abs/2411.03743)。
在相关的工作中,我们验证了通专融合大模型能够提出有效的科学假设。如果把通专融合再进一步延伸至多智能体,我们发现,具备通专融合的系统,可以在科学研究的全生命周期过程中发挥不同的作用,并可与人类科学家进行配合。
我们进而提出了“人在环路大模型多智能体与工具协同”概念框架,用以模仿人类科研过程。通过构建ai分析师、工程师、科学家和批判家等多种角色,同时接入工具调用能力来协同提出新的假设,并进一步将人类专家纳入其中,借助“人在环路”挖掘人机协同的潜力。实验结果表明,这一框架能够显著提升假设发现的新颖性与相关性等多个维度指标(large language models are zero shot hypothesis proposers. neurips 2023,https://arxiv.org/abs/2311.05965)。
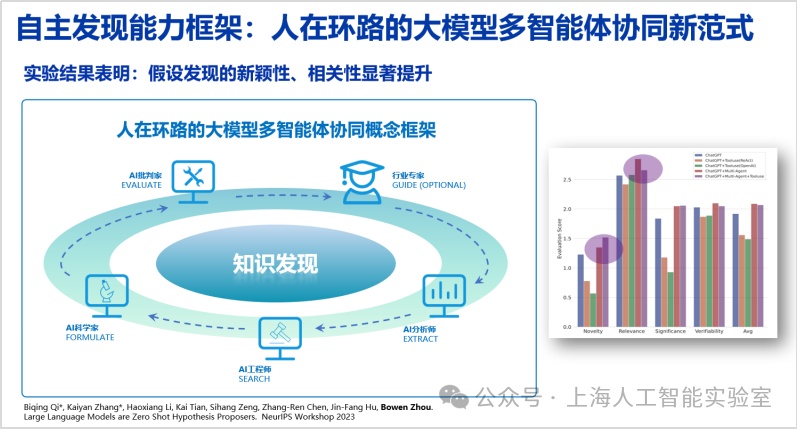
早在1900年,德国数学家大卫·希尔伯特(david hilbert)提出了著名的“23个问题”,引领了数学多个子领域数百年的发展。无论是希尔伯特还是爱因斯坦,他们都谈到过,提出科学问题,远比解决问题更重要。我们希望通专融合的ai系统,能帮助各个领域出现更多希尔伯特。

展望:agi的中心法则?
分子生物学中,有一个被称为“中心法则”的概念,1958年由诺贝尔奖得主佛朗西斯·克里克(francis crick)首次提出,明确了遗传信息从dna传递到rna,再从rna传递到蛋白质的过程。这一法则不仅深刻揭示了生命现象的本质,也为之后的生物技术发展提供了方向指导。随着科学研究的深入,中心法则经历了多次修正和完善,逐渐成为分子生物学的核心理论之一。
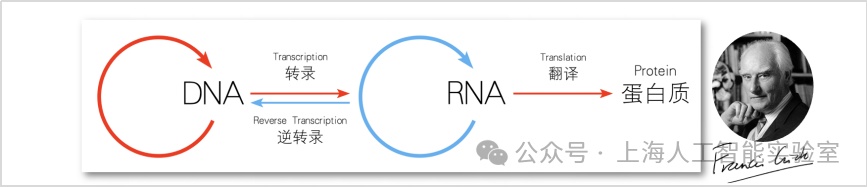
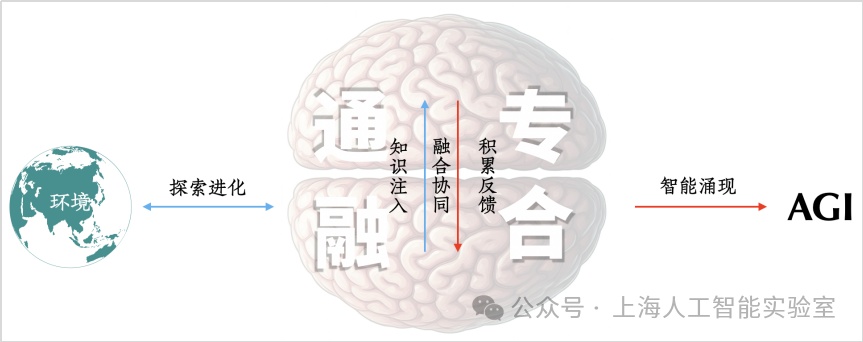
这一法则令我印象深刻。因为它非常有洞察地揭示和影响着生物领域的各个方面。这进一步引发了我的联想:关于agi如何实现,此前还未形成一条指导实践的完整路径,我们能否找到一种agi的“中心法则”?我在报告中提出的“通专融合”路径,是对这一问题的探索。生物学的中心法则是在几十年研究中不断地迭代更新,很多优秀科学家一同共创,做出了杰出贡献。同理,agi可能也需要这样来自人工智能研究与其他交叉学科社区的共创。



